哈希表总结及其高级话题讨论
哈希表(hash table)是一种快速查找场景下常用的数据结构,本文对其主要问题及其高级应对方法进行有限的总结和讨论:
-
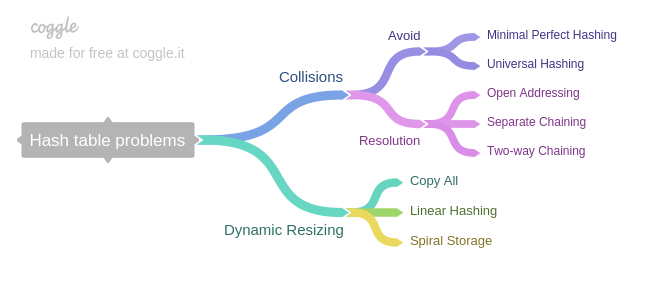
负载不够均衡,此时会有哈希冲突(collision)出现,导致哈希表性能下降
-
负载高时,若不进行空间扩展则性能下降,若进行空间扩展,扩展行为的(瞬间)代价通常较高
先回顾一下哈希表的数学模型:
-
所有数据所在的空间集合为 \(S\)
-
通过哈希表存储的数据集合为 \(U\)
-
所有哈希桶(bucket)的下标集合为 \(R\)
-
通过某种方式将 \(S\) 中的元素映射到 \(R\) 集合,不妨记为函数 \(h\)
一般 \(S\) 的大小远大于 \(R\),但是通过哈希表存储的数据集合 \(U\) 与 \(R\) 的大小相差不会太悬殊。
如果有 \(x \in S, y \in S\) 并且 \(x \ne y \land h(x) = h(y)\),则称 \(x\) 与 \(y\) 冲突(collision)。
如果 \(h\) 可以将 \(U\) 单射(injective)到 \(R\),则称此种情况为完美哈希(perfect hashing)。这意味着 \(U\) 的大小小于等于 \(R\) 的大小。特别的,当 \(U\) 的大小与 \(R\) 的大小相等时,称此种情况为最小完美哈希(minimal perfect hashing)。
如果 \(U\) 预先给定,并且不再进行调整,则称此种情况为静态哈希表(static hash table),否则称为动态哈希表(dynamic hash table)。
哈希冲突
哈希冲突的解决方案有两种:
-
冲突避免
-
冲突解决
冲突避免
如果哈希函数 \(h\) 选得足够好,并且 \(U\) 的大小小于等于 \(R\),就有可能形成完美哈希的情况。对于静态哈希表,有确定性的策略 [1] 可以找到这样的 \(h\) 来达成最小完美哈希。对于动态哈希表,由于我们不能预测 \(U\) 中元素的分布,我们不能预先设计 \(h\) 以达成完美哈希。特别的,由于 \(U\) 中的元素是变动的,\(U \subset S\) 且 \(S\) 的大小远大于 \(R\),因此对于使用确定性策略构成的哈希函数 \(h\),总是存在一个对抗性的集合 \(U\),可以使得哈希冲突尽可能的多。因此,对于动态哈希表,必须使用非确定性的策略来构成哈希函数 \(h\),才有可能保证避免哈希冲突。这一问题称为 Dynamic Perfect Hashing 问题。一个可行的方案是预先准备一族哈希函数,在使用过程中随机从中选择一个哈希函数。可以想象,这一族哈希函数应该具有某种性质,使得相同分布的输入不会产生相同分布的输出。这样一来,针对某一个特定哈希函数的对抗性策略就不会对其他哈希函数生效,因此随机选择哈希函数即可抵抗确定性的对抗策略。当然,这涉及到一个问题,即在查找的时候该怎么知道用哪一个哈希函数进行查找?这一问题在后面冲突解决中的 Two-way Chaining 中进一步讨论。
如果存在这样一组哈希函数,\(H = \{h: U \rightarrow R\}\) 满足 \(\forall x, y \in U, x \ne y: \Pr_{h \in H}[h(x) = h(y)] \le 1/{|R|}\),则称 \(H\) 为全域哈希族(universal hashing) [2]。这一数学式的意义是,在 \(U\) 中任选两个不同的元素 \(x, y\),在 \(H\) 中任选一个哈希函数 \(h\),则 \(h(x), h(y)\) 是独立(均匀分布)的。
全域哈希族的加强形式为全域k哈希(universalk hashing) [3],其需要满足如下条件:给定 k 个两两不等的元素 \((x_1, ..., x_k) \in U^k\),和 k 个哈希值(无需两两不等)\((y_1, ..., y_k) \in R^k\),有
这一加强形式通常不容易达到,因此我们有时选择其宽松型式 \((\mu, k)\)-universal:
其中 \(\mu\) 越接近 1 越好。
冲突解决
经过上面的讨论可知,对于动态哈希表很难达成完美哈希,因此我们必须考虑如何处理哈希冲突。常见的冲突解决策略有:
-
Open Addressing
-
Separate Chaining
-
Two-way Chaining
Open Addressing
Open Addressing 是一种常见的冲突解决策略,其常见的细分策略有:
-
Linear probing
-
Quadratic probing
-
Double hashing
其中 Linear probing 由于对缓存友好,性能最高,比较常用。Linear probing 可能带来冲突聚集的情况,为了避免这一现象,有时也会使用 Quadratic probing 策略。使用 Quadratic probing 也会被对抗性策略所困,因此有时也会使用 Double hashing 配合 Universal hashing 获得更好的效果。
Separate Chaining
Open Addressing 在装载因子较高时性能会急剧下降,为了应对这一情况,也常使用 Separate Chaining 策略。Separate Chaining 一般使用链表,有时也会使用查找树结构。
Two-way Chaining
Two-way Chaining 就像是 Double hashing,区别在于 Double hashing 使用一个哈希表,而 Two-way Chaining 使用两个哈希表 T1 和 T2。在插入时,\(T[h_1(x)]\) 和 \(T[h_2(x)]\) 中哪个装载的元素更少,就插入到哪儿。查找时需要访问两个哈希表。
Cuckoo Hashing
Cuckoo Hashing [4] 是 Two-way Chaining 的进阶版本,其同样使用两个哈希表,但是不再进行 Chaining,而是进行 Evicting,算法如下:
procedure insert(x)
if lookup(x) then return
loop MaxLoop times
x ↔ T1[h1(x)]
if x = ⊥ then return
x ↔ T2[h2(x)]
if x = ⊥ then return
end loop
rehash(); insert(x)
endCuckoo Hashing 不使用 Chaining,意味着这是一种 Dynamic Perfect Hashing 的方案。
P.S. Cuckoo Hashing 论文 [4] 中对其所使用的 \((\mu, k)\)-universal 哈希函数族有着更进一步的优化。
动态大小调整
随着哈希表的装载因子上升,哈希冲突的概率会不断上升,直到装载因子超过 1 时,必然发生哈希冲突(抽屉原理)。对于动态哈希表,由于 \(U\) 的大小不能预先得知,所以必然需要动态调整哈希表的大小。常见的策略是当装载因子超过某一阈值后,线性扩展哈希表的大小为原来的若干倍;当装载因子低于某一阈值时,线性收缩哈希表的大小为原来的若干分之一。使用两个阈值的原因是为了避免抖动。由于 \(R\) 发生变化,因此对应的哈希函数也必须发生变化。调整大小时,另行分配内存,然后将原哈希表中的所有元素 rehash 后存储到新的哈希表中,这种策略称为 Copy All 策略。尽管该操作可以均摊到插入操作中,使得整体的均摊时间复杂度仍为一个常数,但是这一策略会带来较长时间的停顿。为了改善这一问题,又有其他改进策略 [5],其中较为知名的有:
-
Linear Hashing
-
Spiral Storage
-
Extendible Hashing
哈希表不能够均匀地增长,其根本原因在于 rehash,只要能够不 rehash 但是调整 \(R\),就可以解决这一问题。
Linear Hashing
对于任意给定的 \(x \in U\) 或者有 \(h_i(x) = h_{i - 1}(x)\),或者有 \(h_i(c) = h_{i - 1}(c) + 2^{i - 1} N\)。一般来说简单取模即可符合这一要求。
Spiral Storage
Spiral Storage [5] 总是将负载更多的放在哈希表靠前的位置上,而非均匀地将负载分配到整个哈希表中。这样尽管是像 Linear Hashing 一样,总是从哈希表的头部开始进行 bucket 的分裂,也不会有不及时处理非常满的 bucket 的问题。
Spiral Storage 的思路是这样的。哈希表的负载从前向后逐渐降低;扩展大小时,需要将表头的 bucket 中的元素分配到多个新 bucket 中并添加到哈希表的末尾,并且依然保持负载从前向后逐渐下降的性质。假设每去掉表头的一个 bucket 就添加 d 个新 bucket,称 d 为哈希表的增长因子。考虑到哈希表是非线性增加大小的,应该采用一个非线性增长的哈希函数族,将 \(U\) 映射到 \(R\)。易发现指数函数满足这样的性质。为了满足负载逐渐下降的性质,可以将 \(u \in U\) 先均匀的映射到 \(x \in [S, S + 1)\),然后再使用指数函数 \(y = d^x \in R\)。\(R\) 的大小会随着 \(S\) 的变化而指数级增长,并且其中的元素的负载分布是指数级下降的。哈希表扩张时,将原本 \(y = d^x, x \in [S, S')\) 的元素映射到了新的区间 \(y = d^x, x \in [S + 1, S' + 1)\),区间的大小增长了 d。
论文 [5] 中提到了 Spiral Storage 的具体实现细节及一些优化方法。
Extendible Hashing
Extendible Hashing [7] 将 bucket 和 bucket 的索引分别存放,使用 bucket 对应 key 的前缀对其进行索引,这样在扩展哈希表的大小时,就无需复制所有对象调整索引部分即可。
使用场景
单机场景
在 Facebook F4 这种只读存储服务的场景下,或者是批量更新的 Index Serving 场景下,适合使用 Minimal Perfect Hashing 的策略。
对于动态哈希表的使用场景,如果可以预先知道或部分知道数据的分布,则可以针对性的设计哈希函数,以尽可能达到 perfect hashing。
如果没有关于数据的额外信息,则只能考虑冲突避免策略。在可以保证负载因子较低的情况下,应该尽量选择 Linear Probing 策略以较好的利用缓存。不能保证负载因子的情况下,如果需要有最坏情况保证的话,应该考虑 Separate Chaining 平衡搜索树的策略,或者干脆不使用哈希表。希望获得较高的装载因子,同时性能下降不太严重,又可以接受一定长尾的话,可以考虑 Cuckoo Hashing。
哈希表的动态大小调整一般选择 Copy All 策略,这样对哈希函数的限制最小,实现也最容易。个人感觉 Spiral Storage 要比 Linear Hashing 好一些,原因已在上面 [spiral-better] 说明过。Google 有一个 Spiral Storage 的开源实现: https://code.google.com/p/sparsehash/ 。PostgreSQL 中使用 Linear Hashing,见 https://www.postgresql.org/docs/8.0/static/sql-createindex.html 。
多机场景
哈希函数的选择同单机场景。这里只讨论动态大小调整的问题。
尽管在早期有将 Linear Hashing 和 Extendible Hashing 扩展到多机的尝试 [8][9],但是最终被一致性哈希所统治。多机场景下,由于不希望出现单点瓶颈,所以使用 P2P 结构,更多的问题在于如何快速的将请求匹配到实际存储数据的节点。这一问题被归类为如何将对等节点自组织成某种结构,并在其上进行消息路由,这方面的总结见 论文笔记:关于 P2P 的一些综述。这些路由算法的时间复杂度一般都是 \(\mathcal{O}(\log n)\) 级别的。对于 LAN 环境下的快速查找场景,尤其是使用哈希表的情况下,我们一般期望常数级别的时间复杂度,这方面可以参考 [10][11],或者是干脆缓存所有节点的映射信息。
其他
因为哈希表一般需要保持较低的负载因子,在哈希表较大时元素会非常稀疏。如果需要支持 scan 操作的话,需要考虑在非空 bucket 之间建立联系。
如果不在乎计算复杂度的话,可以使用密码学哈希函数(Cryptographic hash function)以获得较为均匀的结果。
References
-
[1] Martin Dietzfelbinger. (2007). Design Strategies for Minimal Perfect Hash Functions. Stochastic Algorithms: Foundations and Applications. SAGA 2007. Lecture Notes in Computer Science, vol 4665. DOI:https://doi.org/10.1007/978-3-540-74871-7_2
-
[2] Carter, J. L., & Wegman, M. N. (1979). Universal classes of hash functions. Journal of Computer and System Sciences, 18(2), 143–154. DOI:https://doi.org/10.1016/0022-0000(79)90044-8
-
[3] Wegman, M. N., & Carter, J. L. (1981). New hash functions and their use in authentication and set equality. Journal of Computer and System Sciences, 22(3), 265–279. DOI:https://doi.org/10.1016/0022-0000(81)90033-7
-
[4] Pagh, R., & Rodler, F. F. (2004). Cuckoo hashing. Journal of Algorithms, 51(2), 122–144. https://doi.org/10.1016/J.JALGOR.2003.12.002
-
[5] Larson, P.-A. (1988). Dynamic hash tables. Communications of the ACM, 31(4), 446–457. https://doi.org/10.1145/42404.42410
-
[6] Hiemstra, D., Kushmerick, N., Domeniconi, C., Paice, C. D., Carroll, M. W., Jensen, C. S., … Mankovskii, S. (2009). Linear Hashing. In Encyclopedia of Database Systems (Vol. 0, pp. 1619–1622). Boston, MA: Springer US. https://doi.org/10.1007/978-0-387-39940-9_742
-
[7] Ronald Fagin, Jurg Nievergelt, Nicholas Pippenger, and H. Raymond Strong. 1979. Extendible hashing — a fast access method for dynamic files. ACM Trans. Database Syst. 4, 3 (1979), 315–344. DOI:https://doi.org/10.1145/320083.320092
-
[8] Witold Litwin, Marie-Anne Neimat, and Donovan A Schneider. 1993. LH*: Linear Hashing for distributed files. Proc. 1993 ACM SIGMOD Int. Conf. Manag. data (1993), 327–336. DOI:https://doi.org/10.1145/170035.170084
-
[9] Victoria Hilford, Farokh B. Bastani, and Bojan Cukic. 1997. EH* - Extendible Hashing in a distributed environment. Proc. - IEEE Comput. Soc. Int. Comput. Softw. Appl. Conf. (1997).
-
[10] Venugopalan Ramasubramanian and Emin Gun Sirer. 2004. Beehive: O(1)lookup performance for power-law query distributions in peer-to-peer overlays. System 1, 1 (2004), 8. Retrieved from http://portal.acm.org/citation.cfm?id=1251175.1251183
-
[11] Tonglin Li, Xiaobing Zhou, Kevin Brandstatter, Dongfang Zhao, Ke Wang, Anupam Rajendran, Zhao Zhang, and Ioan Raicu. 2013. ZHT: A light-weight reliable persistent dynamic scalable zero-hop distributed hash table. Proc. - IEEE 27th Int. Parallel Distrib. Process. Symp. IPDPS 2013 (2013), 775–787. DOI:https://doi.org/10.1109/IPDPS.2013.110
-
[12] Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. 2007. Dynamo: Amazon’s Highly Available Key-value Store. Proc. Symp. Oper. Syst. Princ. (2007), 205–220. DOI:https://doi.org/10.1145/1323293.1294281
-
[13] Vahab Mirrokni, Mikkel Thorup, and Morteza Zadimoghaddam. 2016. Consistent Hashing with Bounded Loads. (2016), 587–604. Retrieved from http://arxiv.org/abs/1608.01350
补充
最近恰巧看到2篇不错的文章: