论文笔记:[SOSP'01] SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
staged event-driven architecture (SEDA) 框架在建模的时候就将负载和资源瓶颈考虑在内,从而可以在高负载的情况下也能工作良好,并且有效防止服务过载。SEDA 架构的基本思想是将业务逻辑切分成一系列通过 queues 连接起来的 stages,组合成一个 data flow 网络去执行。
很久之前就看到过 SEDA 的论文,当时没有太过在意,因为这个 idea 实在是太简单了。最近这几年在多租户系统的隔离性,延迟稳定性方面进行了一些比较深入的工作,又加上最近看到了比较相关的论文和文章之后,突然又产生了一些触动,决定把这篇文章再捞起来写上几句。
我们接下来还是先跟着论文的思路走,然后再补充一些其他相关资料。
相关工作
基于线程并发
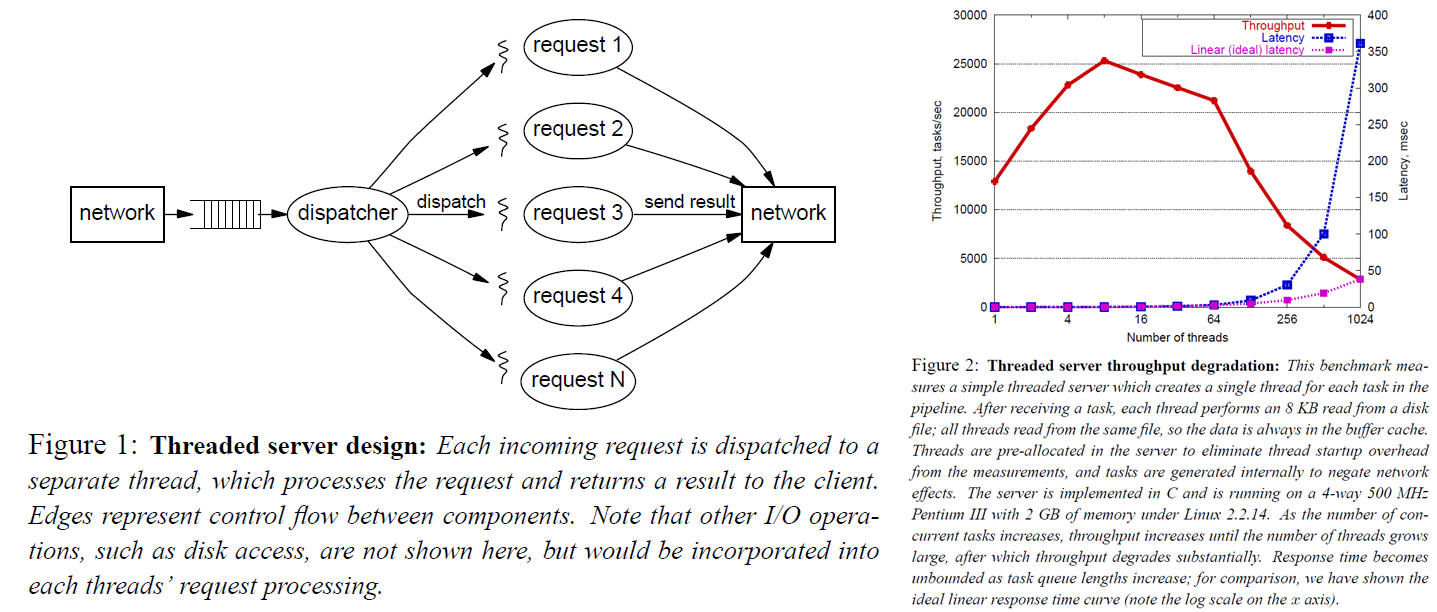
最简单直接的方式就是每来一个请求就启动一个线程去处理。这么做的好处是编程模型极其简单,调度隔离之类的问题都交给操作系统来保证了,也比较可靠。缺点是在负载较高的时候,会产生不可忽视的开销。因为物理资源是有限的,尽管操作系统层面做了一层抽象,使得看起来我们可以获得非常多的资源,但是这都是假象,在高负载情况下会暴露无遗。每个线程分到的时间片都是有限的,非常多的线程在频繁的进行上下文切换,缓存在不断的抖动,线程调度的开销随着问题规模增加而增加,锁资源争用,这些因素都会带来性能的急剧下降。而且线程频繁创建和销毁也会带来可观的开销。从作者给的图表来看,超过系统承载能力之后再持续加压,会导致系统性能下降。我们预期通过某些手段能够自保,从而维持在巅峰性能附近。
基于线程池并发
一个简单的改进方法就是使用线程池。这样的话至少可以解决线程数量过多带来的问题。作者在这里提到,在高负载情况下,这样会带来公平性问题。
公平性问题在多租户系统中确实是一个非常重要的问题,也是系统规模做到一定程度时必须面对的一个问题。这里稍微啰嗦一下,展开说两句。简单来说,多租户服务的资源利用率是远高于单租户服务的。租户足够多,且足够多样性的情况下,有的用户在忙的时候,通常也有一些用户在空闲。这样就带来了整体利用率上的提升。首先我们要做到公平,这样就不会因为有一个人意外使用了特别多的资源,而影响到其他正常使用服务的用户。否则由于用户体验的下降,用户会拒绝使用你的服务。更进一步的,也许我们需要对用户进行分级服务,高优先级的用户可以抢占使用低优先级用户的资源,当然定价可能也是分级的。
作者提到的公平性问题发生在这样的场景下。负载特别高的情况下,我们处理请求的速度跟不上产生请求的速度。大量的请求堆积在任务分发队列,甚至是网络协议栈上。在这种情况下新来的一个请求,其整体延迟应该是排队等待的延迟加上实际执行处理的延迟。而排队等待延迟是不可控的,并且由于过载的问题没有办法得到妥善的调度,因此有违公平性。
这里我部分同意作者的结论。从纯理论的角度上看这个问题,确实没有一个非常完美的解决方法。从比较符合实际情况的角度来看,我们其实还是有些事情可以做的,并且在一些情况下能够取得很好的效果。如果考虑 DoS(Denial of Service)攻击,那别说你的服务了,可能连网络设备都给你打爆了,这种情况下我们已经没办法从软件层面很好的进行一个处理了。更常规的情况是,有部分用户的请求量异常,超出他们自己的配额,但是没有超出整个服务的承载能力,或者超出了整个服务的承载能力,但是不是特别夸张,比如说只超出了一两倍(取决于你业务逻辑的复杂程度)。对于前者,我们通过配额管理,可以在这个请求被调度进行处理的时候,将这个请求拒绝掉,从而避免了执行业务逻辑的负担。通过这种方式,我们可以一定程度上提高我们系统的承载能力。如果负载进一步上升,可能我们拒绝的速度都追不上产生请求的速度,这种情况下,也许我们可以采取网卡队列管理的一些策略,例如 Random Early Discard,进一步提升我们系统的承载能力(但是已经是有损的了)。
作者也举例了一种比较有意思的场景。比如说空闲的时候来了几个比较大的请求,把线程池里面的线程都用上了(但是没有后续排队的请求);然后突然来了一堆小请求,尽管我们如果多一个空闲线程就能处理过来,但是现在没有任何一个活动线程能来得及干这个事情,然后就把等待队列打爆了。这可能需要 case-by-case 的去做一些更精细的策略调整,比如说对请求大小进行分类,避免一种请求把所有活动线程都占了。
这篇论文写的还比较早,而且主要是和 HTTP Server 相关的调研,感觉确实可能模型和数据处理上都比较简单。所以很多时候说线程池模型的时候真的可能就是直接把请求塞到线程池里直接跑,而没有考虑更多的设计。
基于“事件驱动”并发
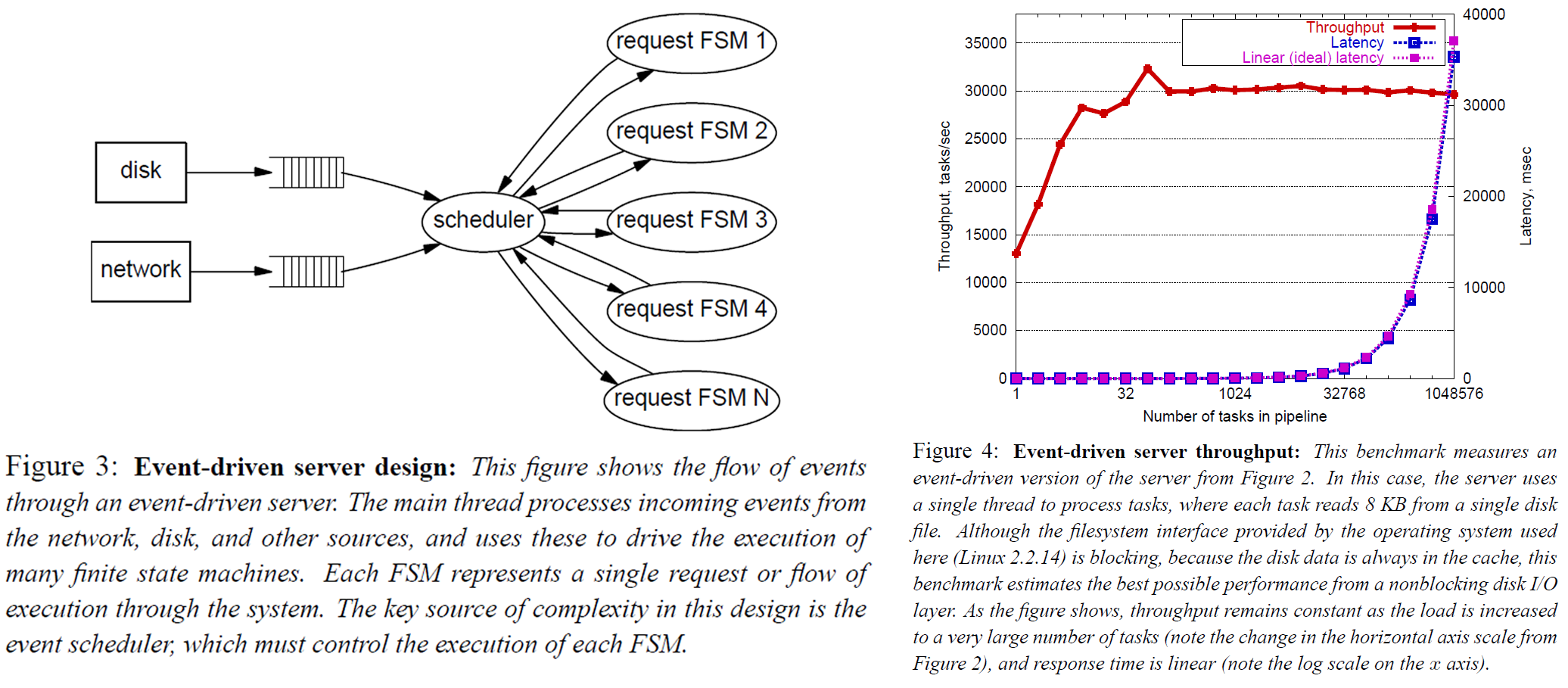
从作者的大致描述来看,感觉就是一个传统的使用 epoll 驱动的事件模型。几乎所有的 blocking I/O 都被转化成了 event,然后再被投递到各个子模块中继续处理。每个子模块自己使用状态机管理状态,这样 request context 就被状态机管理起来,而不是直接放到 thread context 上了。这个模型显而易见的比多线程模型要复杂得多。
-
每个子模块需要小心的维护 request context
-
所有的业务逻辑需要尽可能地避免 blocking,否则可能阻塞 event dispatcher
-
每新增一个子模块可能就需要修改 event dispatcher 的逻辑,特别是调度 event 的逻辑(比如说同一类 event 聚合一波一起处理可能会增加缓存命中率进而提高效率)
Structured event queues
这里就是介绍了一些对 event driven concurrency 的改进工作吧,就大概说了说,我也没看出什么比较有价值的东西,先略过了。
The Staged Event-Driven Architecture
所以总的来说,就是 event-driven 的架构是性能上更好的,但是编程的复杂度也大大上升。是否有可能搞一个模型兼顾性能和开发便利性呢,这就是作者提出来的 SEDA。SEDA 考虑了这些方面:
-
支持大并发量高负载(尽可能使用 event-driven 带来的性能优势)
-
简化系统构建难度
-
系统可以感知当前的负载并以此做出调整(例如降级部分请求等等)
-
系统拥有一定的自我调节能力(例如每个阶段所使用的线程池大小,不是静态指定的,而是根据负载等情况自动调整出来的)
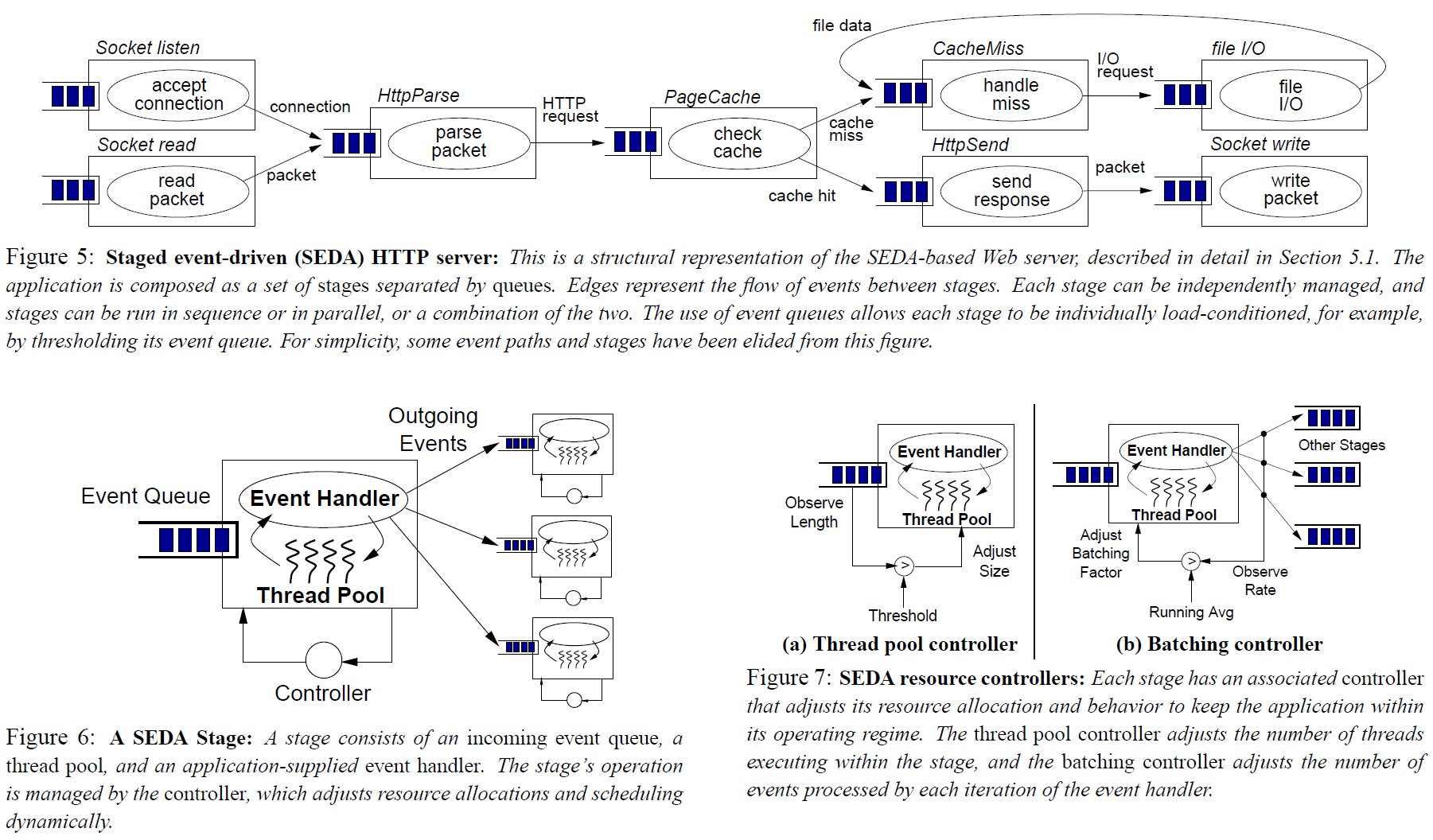
然后这个架构本身没什么太多可说的,因为论文中也没说怎么去划分 stage 合理,大家凭感觉吧……按照我个人的理解,可能在这些地方是需要划分 stage 的。
-
需要的并发度不同
-
需要逻辑分叉
-
需要内部重试,但是内部存在异步操作,所以只能通过类似 requeue 的方式来做
-
逻辑上需要在这里拆开
这种做法有点类似于 actor model(这里就不展开介绍了 actor model 了,感兴趣的可以看看 akka 的文档和 erlang)。但是传统的 actor model 是把线程 attach 到 actor 上而非 mailbox 上的。但是确实看起来把运算资源 attach 到 queues 或者说 scheduler 上可能更合理一些。Apache Hadoop 和 Microsoft Orleans 貌似都是这么做的。
作者在论文里提到了,在 stage 之间是搞一个 event queue 比较好,还是直接做 subroutine call 比较好。论文中说主要是为了解耦。但是后面 retrospective [2] 的时候又说,这里其实才是精髓,要把 load & resource bottlenecks 建模在架构上(也就是这里的 event queue),才能解决 load 高 resource 不足的时候系统行为异常的问题。个人十分认同这一点。
论文里还提到了线程池是可以自我调节的,这里提到了可以调节线程池的线程数和一次执行时候的批大小。带自动伸缩功能的线程池其实不算太少见,但是在设计 API 的时候就考虑批执行的 API 还是比较少见的。以个人的经验来看,批执行确实有可能显著的提升计算能力,主要考虑这些方面。
-
更少的锁争用(拿一次锁可以跑一批数据而非只跑一条数据)
-
更好复用一些临时资源
-
更好的缓存利用
-
可能从 SIMD 指令集中受益
在一些特殊的场景中也有可能使用更复杂的策略。例如在 [3] 中就使用了更复杂的全局策略来优化整体(end-to-end)的计算延迟。
论文后面的部分还有一些细节地方,比如异步 I/O,降级策略等等,和这个核心思想关联性不强,就不展开说了。
A Retrospective on SEDA
一开始简单地说了一下历史,主要是说当时论文关注的点和现在大家关注的点可能有些地方不太一样。另外就是说这个论文是个关于架构而非实现的论文,所以大家不要用梨和苹果对比。
哪里做错了
首先是 stage 的抽象没问题,很好的隔离了不同的模块。但是不是每个 stage 都需要和线程池绑定起来,有些地方可能把 stage 组合起来放到一个线程池上(concurrency boundaries)再去跑更合理。不需要线程池的地方也就不需要 event queue 了,直接方法调用效率更高。这我觉得可能也不需要太多解释,主要就是平时都是在低负载情况下的,没事搞好几个线程池和 event queue 本来就挺奇怪的。而且 stage 这个抽象本身就是逻辑上的抽象,非得跟线程池绑定起来也很奇怪。
然后说了一些实现细节,当时 Java 还没有 non-blocking I/O。总之这方面不关键,就不说了。
哪里做对了
用 Java 写太对了(日常迫害 C/C++)!
在建模的时候就考虑 load & resource bottlenecks。一个原因是你能很直观的看出来瓶颈在哪儿(只需要看看队列哪儿长)。另一个原因是,你的服务不能只在低负载下正常跑,负载逼近极限就凉凉了。
其他
然后还说了说测试集也很重要,有些测试集也压根就没考虑高负载的情况。而且也没考虑到测试内存瓶颈,I/O瓶颈,Socket 压力等等。反正就是吐槽了一下测试设计吧,大家做性能测试的时候引以为戒,也不要轻信这种特定场景下得出的测试数据,参考价值比较有限。
References
-
[1] Welsh M, Culler D, Brewer E. SEDA: An architecture for well-conditioned, scalable internet services[J]. ACM SIGOPS operating systems review, 2001, 35(5): 230-243.
-
[2] Welsh M. A Retrospective on SEDA. https://matt-welsh.blogspot.com/2010/07/retrospective-on-seda.html
-
[3] Xu L, Venkataraman S, Gupta I, et al. Move fast and meet deadlines: Fine-grained real-time stream processing with cameo[C]//18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21). 2021: 389-405.