自制分布式存储系统入门篇:背景介绍
文件系统和关系型数据库系统
提到存储系统,就绕不开成名已久的两大系统:文件系统和关系型数据库系统。这两大系统切实的解决了用户的关键问题,并且演进的比较成熟,是我们实现分布式存储系统的重要参考。
传统磁碟硬盘
首先,我们需要了解一下磁盘的物理特性,这是传统磁盘文件系统的基础。机械磁盘的物理结构大致如传统机械磁盘物理结构示意图所示。
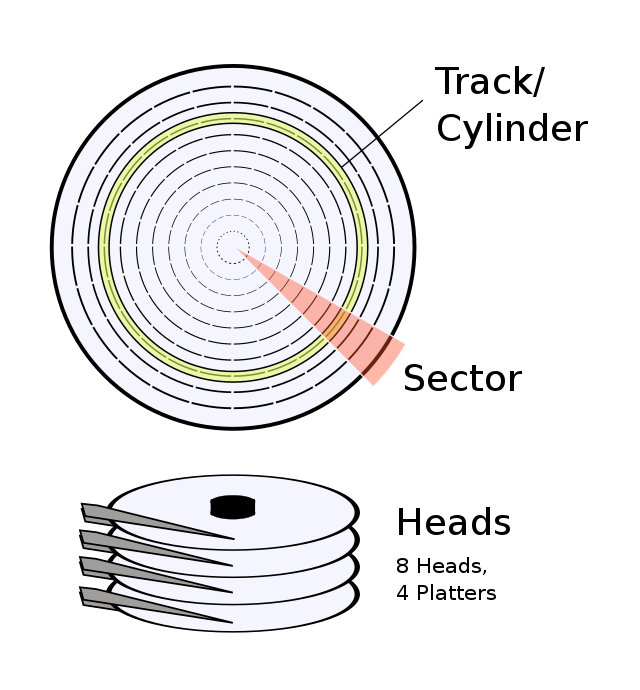
每一个硬盘小黑盒内,都由一组磁盘片组成,每个盘片配套一个机械臂和磁头用于读取盘片上的数据。磁盘运行起来就像是老式留声机一样:
-
盘片持续不断的转动
-
首先机械臂抬起,移动到恰当的磁道位置上
-
然后机械臂落下,磁头读取盘片上记录的数据
显而易见的,磁盘读取数据时,需要花费比较大的代价才能够找到自己要读取的数据的位置,这里面的主要开销有:
-
机械臂抬起,移动到目标磁道,再落下
-
等待盘片转动到目标数据所在的起始位置
但是一旦找到了要读取的数据的位置,读取一段连续的数据的开销比较小。
相关对比数据如每个程序员都应该知道的延迟数据(2019 年)所示[1]。

传统磁盘文件系统
我假设大家对于文件系统提供的接口已经比较熟悉了,在此不过多介绍文件系统接口方面的知识。[2]
传统磁盘文件系统主要解决的是如何在机械磁盘上组织数据,能够安全,方便,快速的存取数据的问题。其基本原理如下[3]:
-
将磁盘视为一堆连续的块,每个块有固定的大小(如EXT2 文件系统的物理结构所示)
-
将其中一些块用于存放目录数据,另一些块用于存放实际数据
-
文件被视为目录数据中的叶子节点,其内容为一系列 指向实际数据块的指针(如EXT2 目录所示)
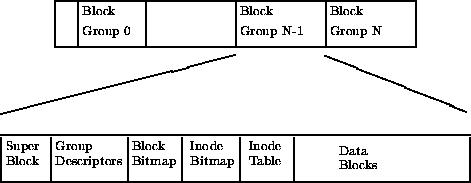
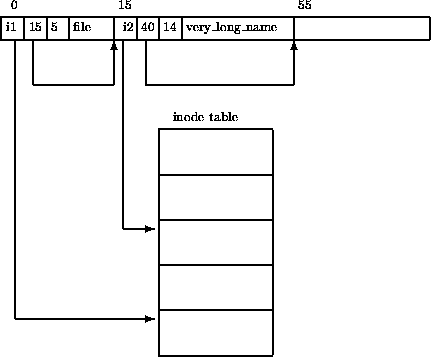
我们在设计存储系统时,也可以参考这一思路,将实际数据存储在一系列数据块中;然后建立这些数据的索引,用于快速访问实际数据。
传统关系型数据库系统
传统关系型数据库的整体架构大致如数据库系统架构图所示。
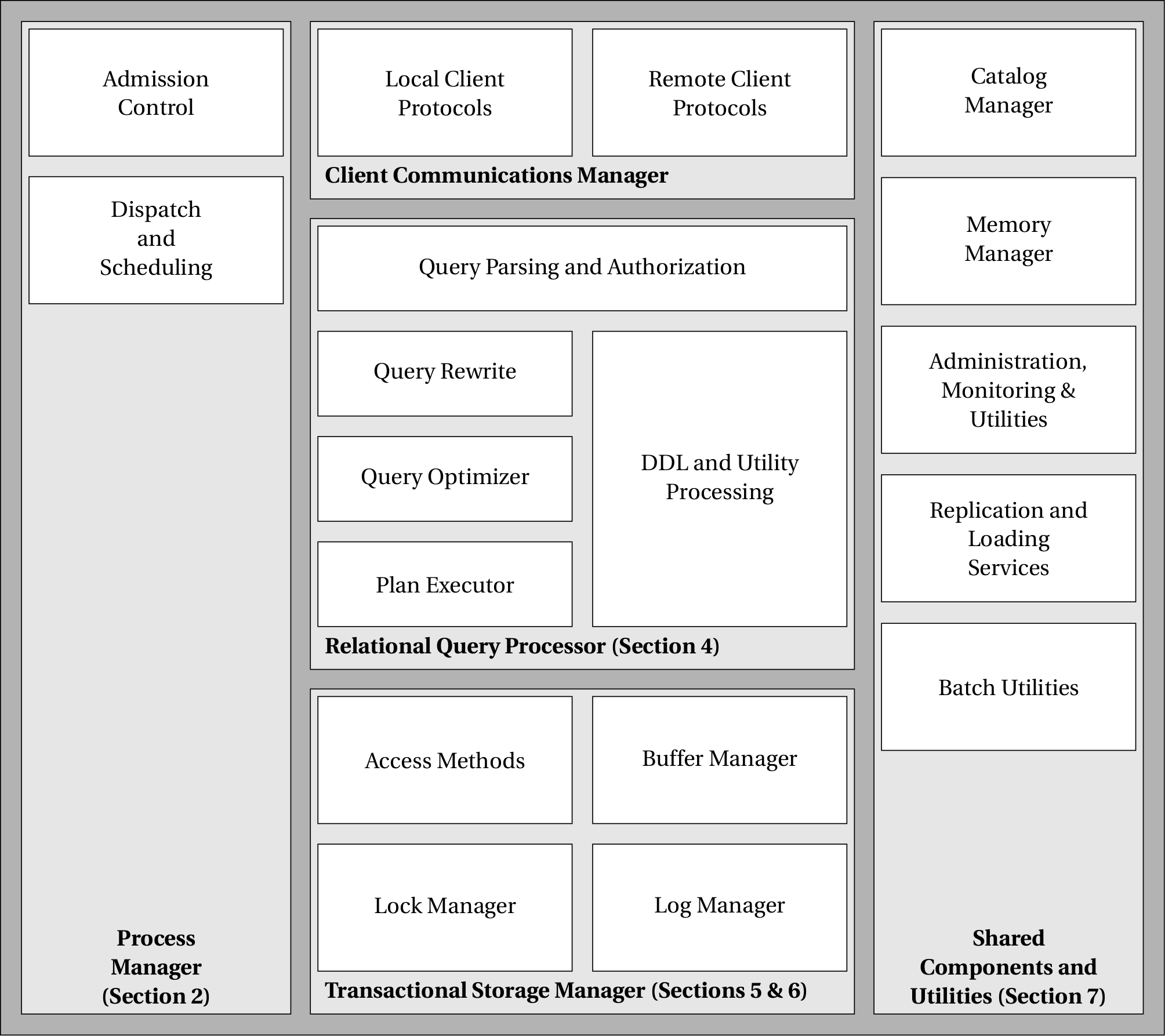
以一次对数据库的请求为例:
-
首先需要和数据库建立持续的连接,这部分由最上面的组件 Client Communications Manager 负责。通常数据库需要支持不同的协议,例如 ODBC 和 JDBC,TCP 和本地 Pipe。
-
用户连接建立后,需要对其是否有权限访问目标资源进行检验(Admission Control),如果通过,则为其分配线程资源(Dispatch and Scheduling)
-
接下来用户的请求进入数据库的核心部分,通过组件 Relational Query Processor 进行处理。
-
用户的 SQL 查询首先被解析成为内部表示形式,通常是对应于关系代数的表达式树。
-
接下来 SQL 查询会被进行优化,在此之前一般会有一个 Rewrite 的步骤对 Query 进行一些预处理以简化 Optimizer 的逻辑。
-
经过优化后的 SQL 查询可能包含多个 Operator,这些 Operator 运算的结果还需要组合和串联,这部分工作由 Plan Executor 来执行。
-
-
Operator 的执行需要数据库底层进行支持,这部分功能由最下面的组件 Transactional Storage Manager 负责。
整个请求处理期间,可能需要从 Catalog Manager 获取表结构,表内容的统计信息等元数据信息。
在我们预计实现的目标系统中,需要关注的点有:
-
访问权限控制(Admission Control),这里面包含几个方面
-
避免用户操作不属于自己的数据
-
避免一个用户占用太多资源,导致其他用户不能正常访问数据
-
-
请求的分发和调度(Dispatch and Scheduling)
-
元信息的管理(Catalog Manager)
-
整个存储的管理(Transactional Storage Manager)
限于篇幅,暂不在此展开讨论,有兴趣的同学可以参考一下论文笔记:[FTNDB'07] Architecture of a Database System
NoSQL 和 NewSQL
传统的关系型数据经历了相当长的一段繁荣时期。但是随着时代的发展,我们产生和需要处理的数据量急剧增长。根据 DOMO 公司的统计,互联网人口数量增长情况如互联网人口增长趋势所示。数据量的增长带来的一个问题是,这些数据难以(不能)在单一机器上得到有效的存储和处理。
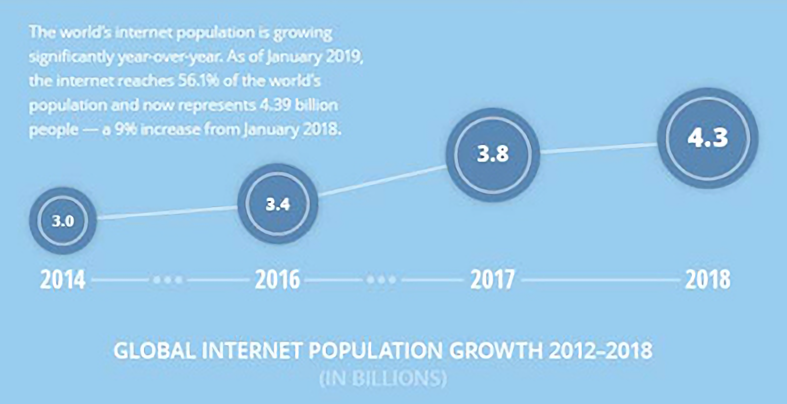
一个比较常见的思路是将数据分布在多台机器上进行存储和处理。传统数据库的分布式方案,江湖俗称分库分表,实际上涉及到两种截然不同的拆分形式:
-
将同一个数据库中的不同表放在不同的机器上
-
将同一个表的不同行放在不同的机器上
前者只要不进行跨表查询,例如 Join 操作,就可以像单机数据库一样使用。遗憾的是,使用传统数据库的主要场景就是基于表之间的关系做查询的,这样的限制还是比较大的。另一方面,随着数据的进一步增长,我们还是面临着一台机器放一张表也有困难的场景,此时就需要将表中的不同行放在不同的机器上。这样做之后,即便是一些简单的 Scan 操作,也需要在多台机器上执行,然后将结果进行一些汇总(聚合)后,再进行使用。
这样的做法表面上好像解决了问题,实际上完全破坏了 SQL 查询接口提供的封装特性。本来我们只需要提供 SQL 语句,数据库系统内部会自动对 SQL 语句进行优化,并完成整套查询操作。但是现在我们不仅要提供 SQL 语句,还要去完成 SQL 执行中的一些功能,例如任务的分发和聚合,而这些功能原本都应该由 SQL 执行引擎(例如 Spark SQL,Flink SQL 等等)去完成。上面说的还都只涉及到普通的查询功能,没有涉及到数据的写入和事务。
这意味着,实际上我们已经不需要单机的系统提供 SQL 层的功能了。我们只需要单机存储系统提供存储相关的功能即可,所有 SQL 层面的工作都应该由所谓的数据库中间件来完成。
另一方面,我们对于单机存储系统又提出了新的要求。由于我们使用更多的机器存放我们的数据并提供服务,整个系统的故障率上升了(\(1 - (1 - \text{单机故障率})^\text{机器数} > \text{单机故障率}\),为了照顾数学不好的同学提示一下,当 \(0 < n < 1\) 时 \(n^k < n\))。我们需要单机存储系统能够组成互备的系统,当一台机器发生故障时,能够自动从另一台机器上恢复数据。
基于这样的背景,NoSQL 运动如火如荼的展开了。表面上看来,大家完全抛弃了 SQL 这一已被证明非常实用的已经发展的比较成熟的存储体系,整体倒退到裸用存储设备的年代。实际上,是整个存储系统从单机系统走向分布式系统的一次涅槃重生。
整体基调虽然确定了,但是具体的实现方式却各有不同。有的人选择实现一个分布式文件系统,理想情况下分布式文件系统的性能和本地文件系统的性能相当,这样的话上层应用几乎无需什么改动,直接跑在分布式文件系统上,就能享受几乎无限大的存储空间。然而遗憾的是,这样的系统在随机访问时的性能仍然难以和本地文件系统相当,更别提 SSD 横空出世后进一步拉大了这一差距。另一方面,即便存储方面的问题得以解决,单机的计算性能仍然难以满足这样的数据量的需求。有的人选择实现一个分布式共享内存系统,这一要求实际上相较于分布式文件系统更为苛刻,因此也因为类似的原因失败了。有的人选择实现分布式对象存储系统(或者叫 Key-Value 存储系统)。这一模型足够简单,但是实际上暗合了磁碟硬盘的模型,即存储空间由一系列 Blocks 组成,因此也得到了较为广泛的应用和很好的发展。
上面说的这些,实际上都是人们还没来得及实现 SQL 时的妥协方案。实际上是先抛开 SQL,解决更原始的问题,之后还是想要把 SQL 加回来的。对于这些方案,称之为 NoSQL 并没有什么不妥。但是在新的时代也确实涌现出了一些新的方法,这些显著不同的方法宣称自己是 NewSQL 或者是 Not only SQL。例如列式存储数据库在部分查询分析场景下的性能可能是传统数据库的 10-100 倍,全内存数据库的 TPS(Transactions Per Second)性能可能是传统数据库的 10-100 倍,等等[4]。